

“Amino Acid Sequences: The Hidden Code of Function” (Part 1)
What Are Proteins, Really?
When you hear the word “protein,” you may first think of food or nutrition.
In reality, however, proteins are molecules that play essential roles in our bodies — they move, react, and form structures, acting as indispensable “workers” at the molecular level.
In scientific terms, proteins are classified as “macromolecules.”
This means they are large molecules made up of many small components linked together.
Their size can range from several nanometers (one-millionth of a millimeter) to more than 1,000 nanometers.
Only 20 Types of Building Blocks: Amino Acids
Proteins are built from small molecules called amino acids.
Remarkably, just 20 different types of amino acids, combined in various ways, give rise to the countless proteins found on Earth.
Each amino acid has a structure centered on a carbon atom (C), to which the following four components are attached:
- Amino group (–NH₂): weakly basic
- Carboxyl group (–COOH): weakly acidic
- Hydrogen atom (–H)
- Side chain: a group that differs among amino acids and determines their properties
Because of this structure, each amino acid possesses its own distinct “personality.”
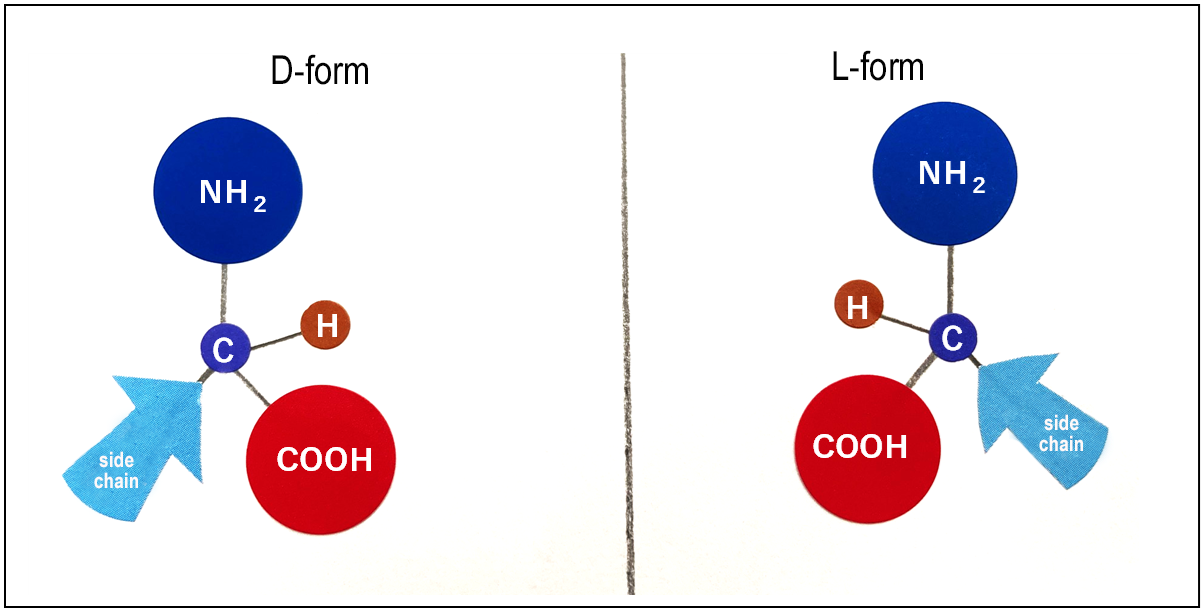
L-Form and D-Form: Two Mirror-Image Shapes
Another fascinating feature of amino acids is that they exist in two mirror-image forms, known as optical isomers (Figure 1).
In natural proteins, almost all amino acids are of the “L-form.”
Isn’t that intriguing?
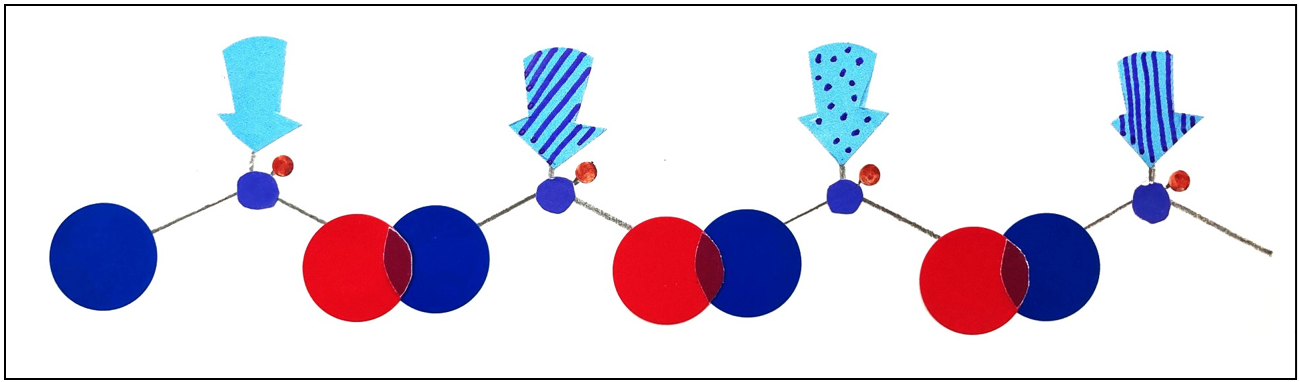
The Power of Order: Why Amino Acid Sequences Matter
Amino acids are linked together through a reaction called “dehydration condensation,” forming chains known as polypeptides or proteins (Figure 2).
The order in which amino acids are arranged — the amino acid sequence — is the single most important factor determining a protein’s properties and functions.
For example, insulin, a hormone essential for the treatment of diabetes, is a relatively small protein composed of just 51 amino acids.
The first person to determine its amino acid sequence was Dr. Frederick Sanger, who received the Nobel Prize in Chemistry in 1958.
The arrangement of amino acids truly represents a “code of life.”
Deciphering this code was one of the central themes of life science in the 20th century.
From Genes to Proteins: The Flow of Information
Today, by reading the DNA base sequence — the order of A, T, G, and C —
we can readily predict the corresponding amino acid sequence.
This flow of biological information is known as the “central dogma”:
DNA → RNA → Protein
Through this framework, we can understand, at the level of blueprints,
what kinds of proteins humans and other organisms produce.
Hidden Mysteries Beyond the Amino Acid Sequence
Even so, knowing the amino acid sequence alone is not enough to fully understand a protein.
Recent research has revealed that specific amino acids can undergo changes known as “modifications” —
for example, the attachment of non-amino-acid molecules or chemical alterations that change their properties.
Such modifications can regulate protein function and are sometimes involved in the development of disease.
This is why it has become increasingly important to directly “see” the shape and motion of proteins —
aspects that cannot be understood from sequence information alone.
Shall We Explore Together?
In this series, we will explore the fascinating world of proteins over the course of twelve installments.
Whether you are just beginning to take an interest in research or encountering the mechanisms of life for the first time,
we invite you to join us on this journey.
New discoveries and surprises surely await.
Author Profile

Toshifumi Takao
Professor Emeritus, The University of Osaka; Ph.D. in Science. From his undergraduate senior year until retirement, he was affiliated with the Institute for Protein Research at The University of Osaka, where he devoted himself to research and education in protein chemistry and structural biology. He is currently a Visiting Professor at the same institute and a Fellow of Life Science Production Division at Rigaku Corporation. In 2022, he was awarded a “Doctor Honoris Causa” in Biochemistry from the University of Havana, Cuba.







